前言
官方教程:Diffusers
本文主要内容:
- 认识 Diffusers 库;
- 基于 Hugging Face 的 Diffusers 库创建自己的扩散模型。
认识 Diffusers 库
介绍
Diffusers 是一种预训练扩散模型库,可用于生成图像、音频甚至是分子的3D结构。
Diffusers 库有三个主要组件:
- diffusion pipelines :用于运行模型进行推理,diffusion pipline 是使用预训练的扩散系统进行推理的最简单方法,开箱即用(注意:pipelines 不能用于训练)。
- noise schedulers :用于控制训练时如何添加噪声以及在推理过程中如何生成去噪图像的算法,平衡生成速度和质量。
- 预训练的模型:可用作构建块,与 schedulers 结合,创建自己的端到端扩散系统。
使用方法
推荐在Colab上学习:https://colab.research.google.com/
安装必要的库。
!pip install --upgrade diffusers accelerate transformers
加载模型,创建一个 DiffusionPipeline 实例,并指定要下载的管道检查点。
from diffusers import DiffusionPipeline
pipeline = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", use_safetensors=True)
DiffusionPipeline 会下载并缓存所有建模、标记化和调度组件。
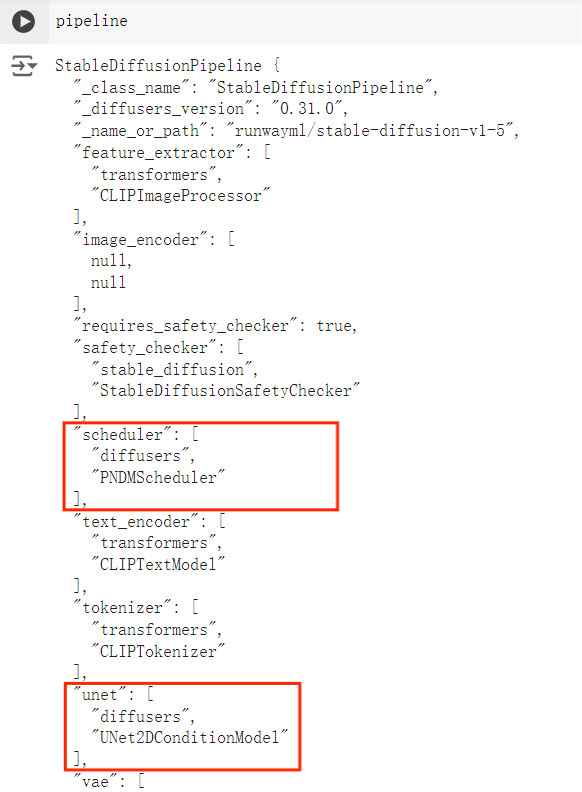
查看 pipeline,会发现 Stable Diffusion 管道由 UNet2DConditionModel 和 PNDMShceduler 等组成。
在”修改“里的”笔记本设置“选择 GPU 硬件加速器,连接后试着修改提示来生成想要的图像吧。
# 在GPU上运行管道
pipeline.to("cuda")
# 将文本提示传递给pipeline以生成图像,然后访问去噪图像
image = pipeline("An image of a dog in Picasso style").images[0]
image
# 保存图像
image.save("dm_dog.png")
这是我的毕加索风格小狗~

不同的调度器具有不同的去噪速度和质量权衡,可以切换不同的调度器来找到最适合的。
# 将默认的PNDMScheduler替换为EulerDiscreteScheduler
from diffusers import EulerDiscreteScheduler
pipeline = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", use_safetensors=True)
# 使用from_config()方法加载
pipeline.shceuler = EulerDiscreteScheduler.from_config(pipeline.scheduler.config)
pipeline.to("cuda")
image = pipeline("An image of a dog in Picasso style").images[0]
image
新的小狗画像出现了。

根据官方教程来试试其它扩散模型吧。
动手创建扩散模型
在“使用方法”的实例中,实际只使用了四行代码(加载模型,创建管道实例,定义文本提示,保存生成的图像)就实现了图像生成。管道包含一个 UNet2DConditionModel 模型和一个 PNDMShceduler 调度器。
我们可以更换Unet模型和调度器来实现自己的扩散模型。
分解一个基本管道
基本知识
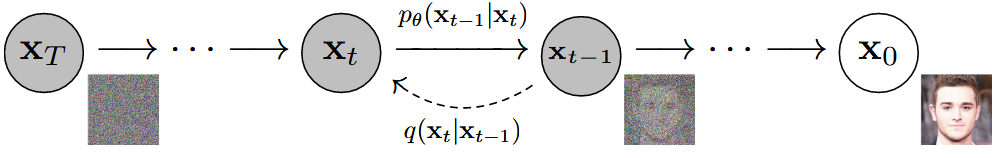
以 DDPM (Denoising Diffusion Probabilistic Models)为例,该模型主要为前向加噪扩散 (data $\rightarrow$noise) 和反向去噪生成 (noise $\rightarrow$ data) 两个过程。模型已经训练好了,我们可以编写自己的去噪过程。
管道通过将与所需输出大小相同的随机噪声多次传递给模型来对图像进行去噪。在每个时间步长,模型都会预测噪声残差,调度器会使用它来预测一个噪声较小的图像。管道会重复此过程,直到它到达指定的推理步长数的末尾。
操作
import torch
# 加载模型和调度器
from diffusers import DDPMScheduler, UNet2DModel
scheduler = DDPMScheduler.from_pretrained("google/ddpm-cat-256")
model = UNet2DModel.from_pretrained("google/ddpm-cat-256", use_safetonsors=True).to("cuda")
# 设置运行去噪过程的时间步常数
scheduler.set_timesteps(50)
# 创建一些与所需输出形状相同的随机噪声
sample_size = model.config.sample_size
noise = torch.randn((1,3,sample_size, sample_size),device="cuda")
设置调度器时间步长会在其中创建一个具有均匀间隔元素的张量,在本例中为 50 个,每个元素对应于模型对图像进行去噪的时间步长。

循环遍历时间步长。在每个时间步长,模型都会执行 UNet2DModel.forward() 传递并返回噪声残差。调度器的 step() 方法会获取噪声残差、时间步长和输入,并预测前一个时间步长的图像。此输出将成为去噪循环中模型的下一个输入,它将重复,直到它到达 timesteps 数组的末尾。
input = noise
for t in scheduler.timesteps:
with torch.no_grad():
noisy_residual = model(input, t).sample
previous_noisy_sample = scheduler.step(noisy_residual, t, input).prev_sample
input = previous_noisy_sample
完成图像去噪后,将去噪后的输出转换为图像即可。
from torchvision import transforms
image = (input/2+0.5).clamp(0,1).squeeze()
# print(image.shape)
toPIL = transforms.ToPILImage()
img = toPIL(image)
img
分解 Stable Diffusion 管道
基本知识
Stable Diffusion 是一种文本到图像潜在扩散模型。在论文 High-Resolution Image Synthesis with Latent Diffusion Models 中提出。
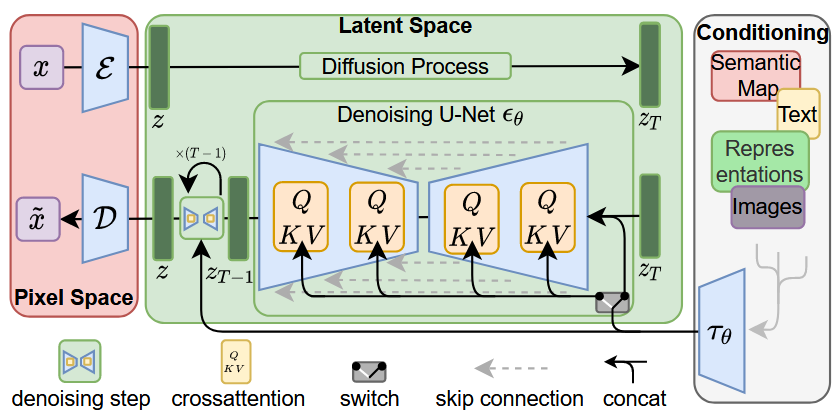
潜在扩散将模型从像素空间迁移到潜在空间,通过在较低维的潜在空间上进行扩散过程来减少内存和计算复杂性。潜在扩散的三个主要组件为:一个自编码器(VAE),一个U-Net,一个文本编码器(如CLIP)。
VAE模型具有编码器和解码器两部分。编码器用于将图像转换为低维潜在表示,即U-Net模型的输入。解码器将潜在表示转换为图像。
U-Net具有编码器和解码器两部分,均由ResNet块组成。U-Net 输出预测噪声残差,该噪声残差可用于计算预测的去噪图像表示。为了防止U-Net在下采样时丢失重要信息,通常在编码器的下采样ResNet和解码器的上采样ResNet之间添加快捷连接。 此外,稳定扩散 U-Net 能够通过交叉注意力层在文本嵌入上调节其输出。 交叉注意力层被添加到 U-Net 的编码器和解码器部分,通常位于 ResNet 块之间。
文本编码器负责转换输入提示,例如 “骑马的宇航员”进入 U-Net 可以理解的嵌入空间。 它通常是一个简单的 transformer-based 编码器,将输入标记序列映射到潜在文本嵌入序列。
操作
# 准备组件
from PIL import Image
import torch
from transformers import CLIPTextModel, CLIPTokenizer
from diffusers import AutoencoderKL, UNet2DConditionModel, UniPCMultistepScheduler
vae = AutoencoderKL.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="vae", use_safetensors=True)
tokenizer = CLIPTokenizer.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="tokenizer")
text_encoder = CLIPTextModel.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="text_encoder", use_safetensors=True)
unet = UNet2DConditionModel.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="unet", use_safetensors=True)
scheduler = UniPCMultistepScheduler.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="scheduler")
torch_device = "cuda"
vae.to(torch_device)
text_encoder.to(torch_device)
unet.to(torch_device)
创建文本嵌入。文本用于对 UNet 模型进行条件化,并引导扩散过程朝向类似于输入提示的内容。guidance_scale 参数决定在生成图像时应赋予提示多少权重。
prompt = ["a photograph of an blue bird flying through the air"]
height = 512 # default height of Stable Diffusion
width = 512 # default width of Stable Diffusion
num_inference_steps = 25 # Number of denoising steps
guidance_scale = 7.5 # Scale for classifier-free guidance
generator = torch.manual_seed(0) # Seed generator to create the initial latent noise
batch_size = len(prompt)
# 标记文本并从提示生成嵌入
text_input = tokenizer(prompt, padding="max_length", max_length=tokenizer.model_max_length, truncation=True, return_tensors="pt")
with torch.no_grad():
text_embeddings = text_encoder(text_input.input_ids.to(torch_device))[0]
# 还需要生成无条件文本嵌入,它们是填充标记的嵌入。这些需要与条件text_embeddings 具有相同的形状(batch_size 和 seq_length)
max_length = text_input.input_ids.shape[-1]
uncond_input = tokenizer([""] * batch_size, padding="max_length", max_length=max_length, return_tensors="pt")
uncond_embeddings = text_encoder(uncond_input.input_ids.to(torch_device))[0]
# 将条件和无条件嵌入连接到一个批次中,以避免执行两次前向传递
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
创建随机噪声。生成一些初始随机噪声作为扩散过程的起点。这是图像的潜在表示,它将逐渐去噪。
# 高度和宽度除以 8,因为vae 模型有 3 个下采样层。
latents = torch.randn(
(batch_size, unet.config.in_channels, height // 8, width // 8),
generator=torch.Generator(device=torch_device),
device=torch_device,
)
# 使用初始噪声分布sigma(噪声尺度值)对输入进行缩放
latents = latents * scheduler.init_noise_sigma
最后一步是创建降噪循环,它将逐步将 latents 中的纯噪声转换为定义的提示描述的图像。降噪循环需要执行三件事:
- 设置调度器在降噪过程中使用的时步。
- 迭代这些时步。
- 在每个时步,调用 UNet 模型来预测噪声残差,并将其传递给调度器以计算之前的噪声样本。
# 创建降噪循环
from tqdm.auto import tqdm
scheduler.set_timesteps(num_inference_steps)
for t in tqdm(scheduler.timesteps):
# expand the latents if we are doing classifier-free guidance to avoid doing two forward passes.
latent_model_input = torch.cat([latents] * 2)
latent_model_input = scheduler.scale_model_input(latent_model_input, timestep=t)
# predict the noise residual
with torch.no_grad():
noise_pred = unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sample
# perform guidance
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = scheduler.step(noise_pred, t, latents).prev_sample
# 解码图像
# scale and decode the image latents with vae
latents = 1 / 0.18215 * latents
with torch.no_grad():
image = vae.decode(latents).sample
image = (image / 2 + 0.5).clamp(0, 1).squeeze()
image = (image.permute(1, 2, 0) * 255).to(torch.uint8).cpu().numpy()
image = Image.fromarray(image)
image

下一篇写如何训练自己的扩散模型。
